

Hey everyone, here is a post on systems architecture. I am making this at the request of my colleague who works in corporate development. This blog aims to be a crash course introduction to what systems architecture is. Why system architecture is important, why every company struggles with it. How do we maximize the delivery of services and not get lost in implementation hell? Ending with a brief introduction to microservices, a popular architectural style.
TL;DR:
- The system architecture is the process of addressing business requirements through new applications, connections, and components.
- Architectural design’s output before development is a system architecture diagram.
- Often, beyond discovering the requirements, the question is what service providers will be used to operate the system.
- There are a lot of models for designing; the best architecture for a company is dependent on.
- Company Culture — if you do not have a talented workforce, building out a complex architecture could land you in implementation hell or even damage your products outright.
- Foundation and scale– what stage of growth is the company at? For a small-scale, a packaged solution like Firebase could be all that you need to empower your app, and your work is probably better spent on improving engagement rather than building out an entire architectural system.
- Avoiding Implementation Hell — where you fail at implementing anything due to them not being close enough to a good solution.
- Event-driven architecture focuses on a user’s actions as an event and centers the business processes around how a user engages.
- At all costs, avoid implementation hell by doing the legwork and ensuring that your stakeholders are knowledgeable enough to deliver accurate and precise business use cases and requirements.
In reality, systems architecture is not that difficult of a concept because software development, just like product development, choosing pepperoni over prosciutto, and taking your next vacation once the world opens up, are all based on decisions. However, even though some of these decisions seem small, they will have lasting repercussions on your business as a whole.
What is Systems Architecture?
Systems architecture is the creation of application-specific software that solves business use cases, use cases in this context can be allowing for real-time changes of app appearance based on user’s action, messaging systems allowing users to communicate, and tracking of your pizza from that questionable restaurant at 1 am on Friday.
I will use examples from my current position, but The Phoenix Project would only supersede my examples: A Novel about IT, DevOps, and Helping Your Business Win by Gene Kim. This novel covers a tech team at an automotive parts manufacturing company attempting to break into the e-commerce space. The company is failing due to competitors already mastering the digital space and emphasizes their transition to technological stability. This Fictitious story covers the issues that a company might face in making a technology system that succeeds.
Phoenix Project is a book exemplifying the principles of Kanban agile development, creating a company culture, and the issues in shipping tech products. Another good read, however not nearly as entertaining, is Microservice Patterns which covers escaping large hard-to-change systems to distributed separated systems to allow for easier changes in production.
Architecture leads are trying to build out systems that meet business requirements, be it performance, scalability, reliability, security, deployment, and fit within the technology stack. So let’s dig into the 6 core areas of what systems architecture has to tackle.
Six Cores of System Architecture
Performance: How fast or responsive a system is if given a set amount of workload and a given hardware configuration. The question to answer is if the system can act on the information received. This could be on a real-time basis or a batch day cycle based on the business use case. Core principles are (Efficiency, Concurrency, and Capacity).
Scalability: How much load can the system handle in case there are spikes of use? Basically, it is the system’s ability to increase its throughput by adding more hardware to handle increased use?
Reliability: How likely is the service to fail, and does the system remain available? How do we improve fault tolerance? If a fault happens, why did that fault happen, and how do we recover the data?
Security: how to securely transfer, store, and authenticate/authorize. Also, what steps do we need to take to secure systems from internal and external threats? This includes network security, identity management, access management, and common attacks.
Deployment: Most commonly under the scope of the DevOps team, but architecture needs to think about the deployment in production, and in many small teams, the architecture team is also handling DevOps. Requires a lot of automation and coordination with other teams; this addresses how we deploy (applications, infrastructure, and operations), how we handle large-scale deployments (virtual machines, Docker containers, Kubernetes), and finally, how to upgrade systems in production (rolling upgrades, blue-green deploy, recreate deploy, canary deploy)
Technology Stack: What we chose to run the service is based on the requirements of the system. There are a wide variety of service providers that can help address these questions — check this out. Platforms for (web apps, services, data stores, analytics), platform functionality, platform architecture (performance, scalability, reliability) use cases, end-to-end
There are a lot of sub-topics under these six topics. I will cover these topics greatly in individual posts, but let’s keep it simple for now. What these bullet-pointed topics aim to show you is that system architecture is just balancing these 6 areas with the requirements delivered by stakeholders; system architects then choose service providers based on team knowledge, proficient coding languages, and the timeframe for delivery and go through the iteration process to ship a workable solution.
Now that we have a brief explanation of what systems architecture is, how do we show system design to stakeholders? An architectural diagram shows the overall outline of the software system and the relationships, constraints, and boundaries between components.
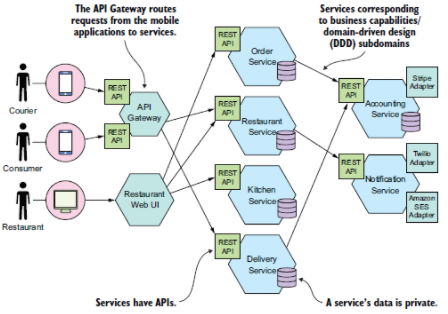
Example Technical Diagram for a Food Delivery App
This diagram taken from Microservices Patterns by Chris Richardson aims to show how each service communicates. In this case, we see that all the customer interactions and courier actions are routed through a gateway and delivered to the corresponding services. This technical diagram shows a microservice infrastructure. However, the principle is that system diagrams aim to show a complete picture of communications in an architectural system.
Another case of communicating a company’s system architecture is Bytedance’s, a pretty straightforward method to demonstrate what each service does.
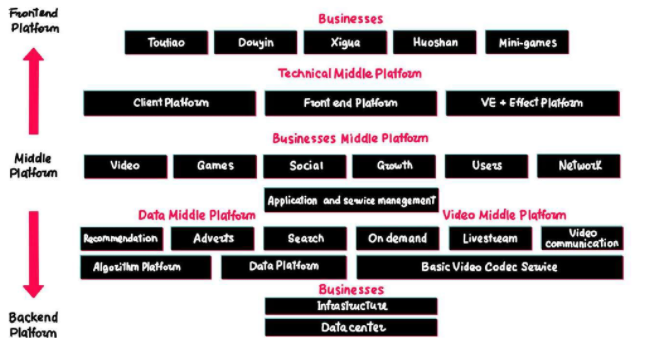
Bytedance’s System Architecture Showing their backend platform
These are just two ways of displaying architecture information. There are more like development view, process view, etc. Systems architecture requires diagrams to show how all the systems relate and detail how they connect to the final business output. These diagrams, while different in style, are supposed to:
- Remove the miscommunication that causes implementation hell
- Make decisions on whether or not the design solves the need of the business
- Reduce the possibility of misinterpreting the system architecture
Next, we will look into why system architecture can be difficult on a company level.
Why Do Companies Struggle with Architecture
I can’t hear you, or I am not Listening
Well, architecture is hard, and it changes as your business does. It especially gets harder when you build from the roof down. A lot of the reasons why companies struggle is because the communication structure is broken, i.e., you build a CMS that disrupts the workflow of business users, or business users cannot adapt to the new tool. Conway’s law poses.
“Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.”
This points to that if a company has a, let’s face it, bad communication structure, they produce bad software. At the same time, the inverse is true for companies that can communicate well. I will give you an example from Spotify. Spotify was archetyping their event-driven architecture, and they had to make a value judgment on what data is of the utmost importance to their business. They resolved that the business-critical data includes metrics such as the EndSong event, which is fired when a user finishes a song. This event is the backbone of the royalty system that they pay to artists and labels. Event Types are prioritized and may differ based on some of the properties listed below:
- Business Impact Event Types – some are used to pay royalties to labels and artists, and some are used to calculate company key metrics. These Event Types are subject to external SLAs both for timely delivery and quality.
- Volume Event Types – are emitted a few hundred times an hour, and some are emitted 1M+ times a second.
- Size Event Types – size varies between a few bytes and tens of kilobytes.
What Spotify could do is identify what matters the most to the business and then build out the system around that requirement. Building out event streams to send real-time or batch processing events to satisfy service level objectives, so their royalty reporting was always correct. In contrast, other events are correct; they take a long time to be received. In this case, we can only assume that someone in commercial communicated this as “we need 100% accuracy on EndSong event to ensure we are paying labels their required amount.” The architecture team created specific event streams depending on importance, and there we go — a working product.
We can’t change our foundation.
Systems architecture changes based on a company’s scale and ability to handle complexity. Google’s Firebase platform is a great tool for getting your app running. However, it is a Google-hosted solution with limitations in what it can offer. Firebase has innate integrations and combines its own solutions such as Firestore real-time database with many developer tools such as A/B testing, authentication, push notifications, segmentation, etc. However, it is not as configurable as a Parse server, a general-purpose back-end solution that requires a lot of knowledge but more customization in building systems.
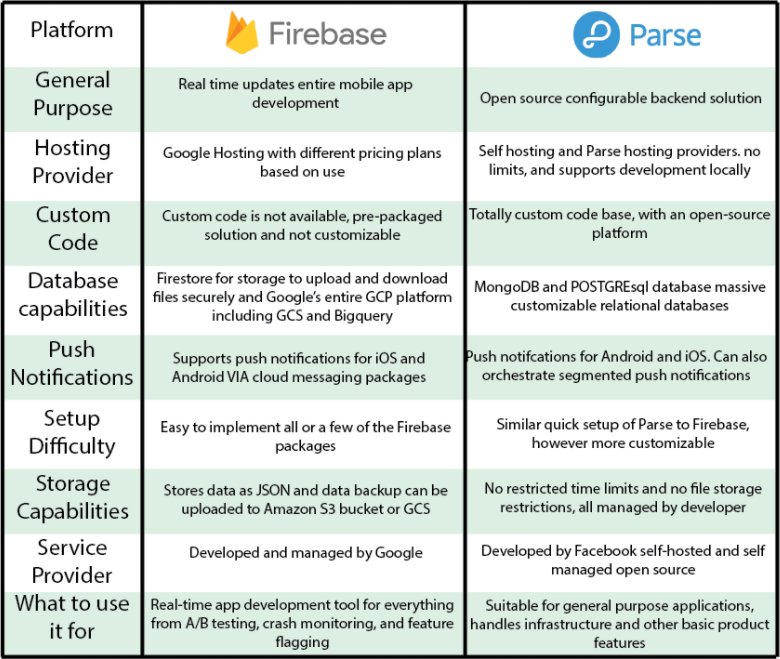
Overview of the differences between platforms
These two platforms are just examples of the considerations architecture teams need to make when deciding on service providers. Firebase works for scaled and new apps, but changing platforms to have more customization can cause migration headaches. The largest and most intimidating task for companies transitioning from that foundational architecture limiting them to open-source configurable architecture can shift third-party service providers. There is a business for everything; mediation platforms, mobile measurement platforms, and app development tool kits such as Firebase are built to make getting a product functioning easy. But moving to an in-house approach to capture all data and deliver customizable experiences is immensely difficult.
At different stages in a company, the leadership needs to make decisions on tools; one example is Twitter, as referenced in Reforge’s article on managing tech debt. Technical debt means that the company opted for an option where they will have to rework all of their systems in the future.
“Instead of building an in-house system early on, they relied and contributed to open source databases. This was likely because teams were moving so fast on other business-critical priorities (acquiring users, shipping features, monetization, IPO prep).”
The fact is technical debt can follow a company like a black cloud, and that rain will come, but you can delay it to the best time possible. However, when technical debt comes, make sure to know how to migrate. Migrating infrastructure is difficult. Migration can stop implementing better systems and cause your company to be stuck in a place known as “implementation hell” where you cannot innovate and cannot extend your engagement, retention, and monetization. With these in mind, Spotify identified a couple of good methods to ease migration. With a focus on making migrations a product and making owners accountable for the success, they tread carefully but still make progress.
What is Implementation Hell
Short answer, the scariest place ever. I have been in this spot multiple times. As a service provider, most of the customers in my main projects are my coworkers. I know; it sounds terrible, right? Well, it actually isn’t when needs collection is done well. However, when needs collection is done poorly, it takes months out of your life, causes tensions in the workplace, and makes you lose hair in the process.
Needs collection for service design takes a lot of inputs, and without everyone being committed and putting in some critical thinking, you will fail to ship something that works as intended. When shipping a product that there is no use for or a product that has uses but makes other jobs more difficult, you could land yourself in a place where teams do not want to implement your product because it does not satisfy their use cases (new or old). Your product could even be harder for operations — regardless of if it solves that core use case identified at the start of the project.
Event-Driven Microservices: Let’s Get Through the Buzzwords
Microservices is an architectural style that aims to set systems assets of independent services that each serve one functionality, i.e., handling one set of business logic. It could be handling a leaderboard, altering a user’s friend lists, and managing a shopping cart.
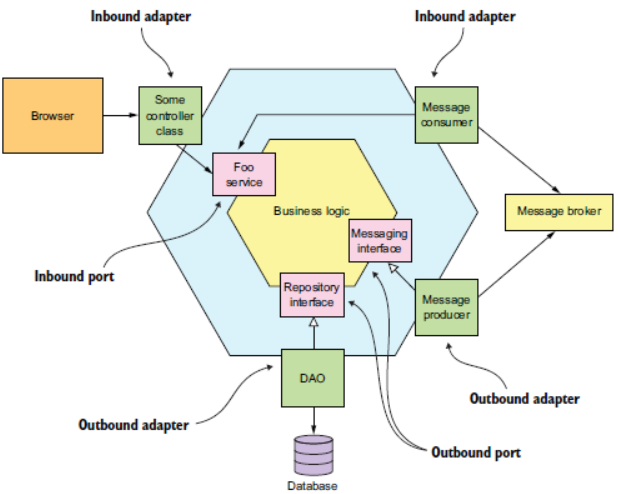
Microservice Hexagonal Structure
The typical microservice might look like this, with a business logic at the core, something as simple as adding an item to a basket or handling OLTP speed real-time processing to handle leaderboards. This service is entirely decoupled with its own messaging service and database to store the corresponding data that the service needs to consume.

Netflix’s Visualization of their Microservices Architecture
As you can see from Netflix’s example, they have independently operating services that only send some data to each other and operate in entirely separate instances. Each of these circles is a microservice that handles one process and delivers the data forward, with events being the main source of information that passes to the endpoints like a DWH.
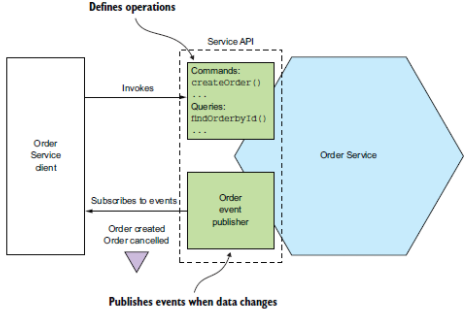
Example of an order service API in a possible microservice architecture
Services might be loosely coupled where all interactions via an API, allowing for deployment of the service without impacting the client. Services might all share a library where all services can consume the same resources to speed up the development and shipping processes of new services.
Microservices are currently a buzzword that is mentioned a lot. Being an architectural style means that it is not the best case for all companies. I will dig into all of that in a separate post only on microservices. However, there are main questions. What is the orchestration service, i.e., the API gateway handling all the traffic? Where is the final data used in the business stored in a user database or a data warehouse? Where does all of this data get combined? How do we handle data normalization and combine all the events of a user into a single stream? Microservices mean a lot more replicated data. How do we tackle replication and keep consistency? Do we need to know how many times a user touched the subscription button? Would that data be passed from the subscription service, or do we only care about conversions? Microservices require a lot of question-asking, but so does all of systems architecture.
To try to keep this blog post brief. Companies can decompose their current systems into their business logic by finding the seams in which service boundaries can emerge. By getting good at finding these seams and working to reduce the cost of splitting out services, companies can grow and evolve their systems that are some of the principles of domain-driven design and microservices — rest to the touch on later
If you have made it this far, thank you for reading my blog. This is blog serves to document my ideas, learnings, and applying concepts to my min-max framework. Check out this first official post on product development. I am happy to converse with all — reach out at cam@min-max.tech